들어가며
MetaData와 프로젝트를 진행하게 된 기업은 블로그 포스트 형식의 Job콘텐츠를 정기적으로 발행하고 있습니다. 콘텐츠가 제공 서비스의 전부는 아니지만 사용자들을 유입시키는 데 중요한 요소로 작용하고 있었습니다. 해당 기업은 유저를 늘려 서비스를 활성화하고자 했고 그 일환으로 몇년 간 유지되던 사이트 디자인을 모두 바꾸었습니다. 또한 사용자들의 유입 창구인 콘텐츠를 가공하는 데 힘을 쏟고 있었습니다.
좋은 콘텐츠가 좋은 유저를 유입시킬 것이라는 당연한 생각으로부터 출발하여, 콘텐츠와 유저에 집중하여 분석을 진행하기로 하였습니다.
본격적인 분석 전, 콘텐츠 분석을 위한 Data set 만들기
1. Google Analytics
이번 프로젝트를 진행하며 가장 많이 활용한 데이터는 구글 애널리틱스 데이터입니다. 구글 애널리틱스(이하 GA)는 웹페이지에 접속한 이용자의 로그 기록을 확인할 수 있는 툴입니다. 주로 웹/앱 서비스의 마케팅 도구로 쓰이고 유저 분석에도 사용됩니다.
일차적으로 GA를 탐색하며 콘텐츠와 관련된 사용자들의 행동을 파악할 수 있었고 다음과 같은 지표들을 분석에 활용하기로 하였습니다.
 < 구글 애널리틱스 화면 예시 >
< 구글 애널리틱스 화면 예시 >
- 유입 채널 : 사용자들이 사이트로 유입한 경로
- 페이지 유입, 이탈률 : 해당 페이지에 유입한 사용자 수와 이탈한 비율
- 페이지뷰 : 페이지가 사용자에게 노출된 모든 횟수
- 세션수 : 30분 단위로 업데이트 되는 사용자의 사이트 방문 수
- 체류 시간 : 사용자자 페이지에 머문 시간
각 지표에 대한 자세한 사항은 여기를 참고하세요😎
2. Python을 이용한 웹 크롤링
콘텐츠 분석에 필요한 가장 중요한 데이터인 ‘콘텐츠’는 Python을 이용해 크롤링했습니다. 기업의 서비스 데이터베이스에 접속하면 쉽게 콘텐츠 데이터를 얻을 수 있지만 보안의 문제로 접근 권한을 얻지 못했습니다.
크롤링을 통해 가져온 콘텐츠는 당시 94개로 다음과 같은 요소들로 이루어져 있습니다.
- 링크
- 콘텐츠 생성 날짜
- 카테고리
- 콘텐츠 제목, 미리보기, 텍스트의 내용
- 텍스트 길이
- 좋아요 수
- 글쓴이 공개 여부
- 관련 콘텐츠 개수
3. GA 데이터와 크롤링한 데이터 합치기
GA 데이터는 매일 수치가 달라지기 때문에 분석 시점에서는 실시간 데이터가 필요했습니다. 그때마다 GA에 접속하고 csv 파일을 받아야 했습니다. 좀 더 간편한 방법이 없을까 고민하던 도중 Google Analytics Spreadsheet Add-on을 알게 되었고 이 프로그램을 이용해 구글 스프레드 시트로 실시간 GA 데이터를 원하는 지표들만 골라 가져올 수 있었습니다.
크롤링한 데이터와 실시간으로 뽑은 데이터는 스프레드시트에서 하나로 합쳐 분석을 위한 데이터 셋으로 활용하였습니다.
 < 스프레드시트에서 구글 애널리틱스 데이터 가져오기 >
< 스프레드시트에서 구글 애널리틱스 데이터 가져오기 >
4. 콘텐츠 탐색을 통해 추가된 데이터들
텍스트로 되어 있는 콘텐츠를 분석하기 위한 방법을 고민하던 중, 각 콘텐츠가 일정한 형식으로 구성되어 있음을 발견하였습니다. 콘텐츠들의 주제는 물론 모두 다르지만, 그 글로 전달하고자 하는 바, 즉, 내용의 요소들이 9가지로 분류 되었고 각 요소들은 다시 다음과 같이 크게 세 부분으로 나누어 볼 수 있었습니다.
- 일반적인 기업/직무의 정보나 필요 역량 등의 요소를 포함하는 글
- 자기소개서와 면접 등과 관련된 팁 요소를 포함하는 글
- 위의 요소들과 다른 요소를 포함하고 있는 글
모든 콘텐츠들을 하나 이상의 요소를 반드시 포함하고 있었고 저희는 그것을 바탕으로 각 콘텐츠가 가장 많이 담고있는 상위 네 가지 요소를 찾아 데이터셋에 추가하였습니다.
이로써, 본격적인 분석에 들어가기에 앞서 저희가 이용할 최종 데이터셋이 완성되었습니다! 짜잔!
콘텐츠 분석하기
텍스트에 언급된 키워드 빈도 분석
‘미리보기’의 키워드로 어떤 내용의 콘텐츠들인지 확인해보자!
94개의 콘텐츠에 대한 데이터셋을 이용하여, 무엇을 할 수 있을까? 어떤 요소를 먼저 보아야 할까?를 끊임없이 생각해 보았습니다. 그러던 중, 콘텐츠의 미리보기가 눈에 띄었습니다. 처음 유저의 관심을 끌고 추후에 글을 눌러, 유입시키는데 중요한 역할을 하기 때문입니다. 그렇다면 미리보기에는 이미 콘텐츠들의 주제가 담겨있지 않을까?라는 생각을 하게 되었습니다.
 < Wordcloud를 이용한 미리보기 텍스트 시각화 >
< Wordcloud를 이용한 미리보기 텍스트 시각화 >
각 콘텐츠의 미리보기 텍스트들을 모두 모아 가장 많이 언급된 단어들만 추려 시각화 해 본 결과, 위와 같은 결과가 나타났습니다.
- ‘업계’, ‘성격’, ‘광고’가 가장 많이 언급 되었고
- ‘중점’, ‘변화’, ‘권리’, ‘입사’ 와 같은 단어들이 그 다음으로 언급되었습니다.
이것을 보았을 때, 대부분의 콘텐츠는 전반적인 업계의 흐름을 짚어주는 내용, 취업 준비생들을 위한 내용, 혹은 특정 직무나 산업에 대한 내용을 미리보기에 나타냄으로서 이용자들의 유입을 끌어내고 있었습니다.
그렇다면 본문의 내용엔 어떤 단어들이 많이 언급 되었을까?
위의 미리보기에서 명사를 추출한 것과 같은 방식으로 본문에 언급된 키워드들도 추출해 냈습니다. 가장 많이 언급된 상위 7개의 단어는 다음과 같았습니다.
- ‘업무’, ‘지원’, ‘회사’, ‘경험’, ‘생각’, ‘기업’, ‘준비’
역시 미리보기 키워드들로 유추해 본 콘텐츠의 내용과 얼추 비슷해 보입니다. 이제 이 키워드들을 어떻게 분석할 지에 대한 고민을 하기 시작했습니다.
최다 출현 키워드가 포함된 글이 유저의 흥미를 유발했을까?
앞서 구했던 키워드들이 가장 많이 포함된 글들은 일반적인 직무와 업무의 정보와 관련된 내용의 글들이었습니다. 과연 이들이 유저에게 흥미를 유발하고, 따른 콘텐츠들을 둘러보게 만들었을까?에 관한 궁금증이 생겼습니다. 이를 확인해보기 위해 상관계수를 살펴보기로 하였습니다.
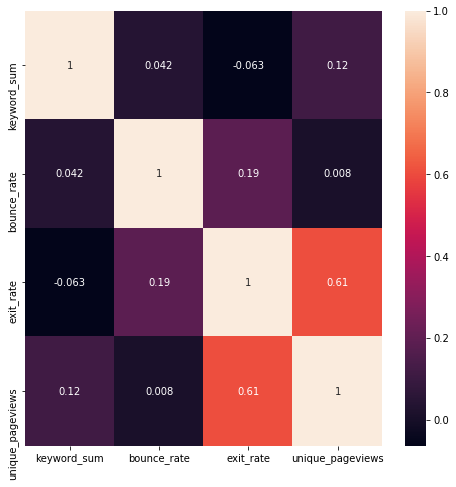
< 콘텐츠에 빈출 키워드가 포함된 횟수와 여러 GA지표들 간의 상관관계 히트맵 >
먼저 상관계수란, 두 변수 사이의 선형적 관계를 보여줄 수 있는 계수입니다. 대략적으로 상관계수의 절대값이 0~0.2 정도일 때에는 ‘선형 관계가 없다’, 0.3~0.6 정도일 때엔 ‘선형 관계가 보인다’, 0.7~1.0 사이라면 ‘뚜렷한 선형 관계가 있다’ 고 결론 내릴 수 있습니다. 위의 7개의 빈출 키워드가 본문에서 언급된 횟수를 세어 상관계수 히트맵을 그려본 결과, 각 콘텐츠와 이탈률, 종료율, 페이지뷰와 큰 선형적 관계가 보이지 않았습니다.🤔🤔🤔
따라서 단순히 많이 언급되는 키워드 뿐 아니라, 좀 더 내용적인 측면에 집중해 보기로 하였습니다.
텍스트의 내용적 요소 분석
콘텐츠에 내용 요소가 많으면 좋을까?
처음 만들었던 데이터셋을 이용하여, 내용적 부분에 중점을 두어 바라본다면 무엇을 볼 수 있을까요? 초기 접근은 늘 그래왔듯 가장 직관적으로 생각하여 보았습니다. 내용요소(subject)가 절대적으로 많은 콘텐츠에 상대적으로 많은 정보가 담겨 있으며, 이것이 곧 이용자들이 다른 콘텐츠도 둘러보게되는 요인이 될 것이라고 생각했습니다. 따라서 요소의 포함 개수(1-4개)와 각 콘텐츠 페이지의 이탈률 포함 여러 요소들과 다시 상관계수 히트맵을 그려서 확인해 보았습니다.
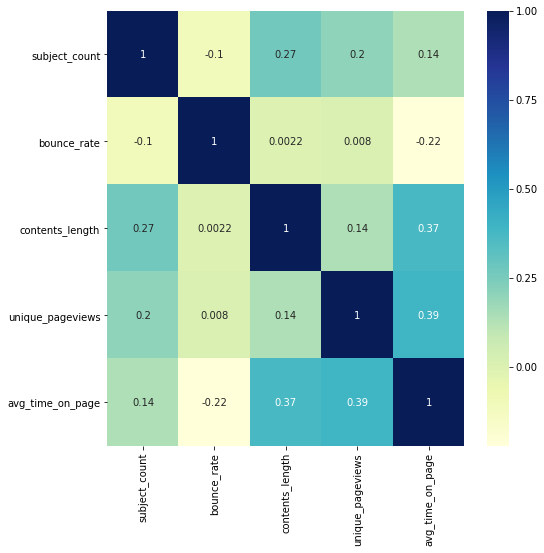
< 요소(subject)의 개수와 여러 GA지표 간 상관관계 히트맵 >
상관계수 히트맵을 그려 확인해 본 결과, 그 동안과는 다르게 진한 부분이 많이 나타나 잠시 눈이 동그래 졌지만, 내용을 찬찬히 보고 나니 이성과 허탈감이 돌아왔습니다.
- 요소 개수 VS 이탈률: 가장 중요한 부분이었던 이탈률과의 상관계수는 -0.1로, 선형적인 관계는 거의 없다고 볼 수 있었습니다. 굳이 따지자면, 계수가 음수이기 때문에 요소개수가 많아질수록 이탈률이 적어지는 반비례의 관계가 있었습니다. 하지만 계수의 크기가 너무 작기 때문에 아쉽지만 유의하다고 보기엔 힘들었습니다.
- 요소 개수 VS 콘텐츠 길이: 요소의 개수와 콘텐츠 길이와의 상관계수는 0.27로 어느정도 비례하는 관계가 보였습니다. 하지만 이는 너무나도 당연한 결과라는 생각에 이르렀습니다. 요소의 개수가 많다는 것은, 콘텐츠에서 그만큼 많은 내용을 포함하고 있다는 이야기이고, 아주 자연스럽게 콘텐츠의 길이가 길어질 수 밖에 없기 때문입니다.
- 요소 개수 VS 평균 머문 시간: 앞선 결론에 매우 관계가 깊은 내용으로, “요소가 많다 > 콘텐츠가 많은 내용을 포함한다 > 콘텐츠 길이가 길다 > 읽는데 오래 걸린다”고 해석될 수 있었고 이는 두 번째로 너무 당연한 이야기가 되었습니다.
별 다른 소득 없이 요소분석이 종결될 수는 없었습니다. 이제 표면적으로 드러나는 부분이 아닌, 진정한 내용에 관한 콘텐츠 분석이 필요한 시기였습니다.
어떤 콘텐츠 요소(subject)가 포함되어야 할까?
단순히 개수만을 비교하는 것이 아니라 이번에는 요소의 내용에 초점을 맞추었습니다. 콘텐츠를 요소에 따라 나누어 그룹 별 이탈률의 평균을 통계적으로 비교해보았습니다. 통계적 분석 방법은 one-way ANOVA 분석을 이용하였습니다. (간단히 첨언하자면, ANOVA 분석이란 분산을 비교하여 여러 그룹 간 평균의 차이를 통계적으로 검증할 수 있는 통계적 검정 방법입니다. 자세한 설명은 이곳을 참고하세요.)
처음엔 콘텐츠를 요소 별로 묶어 각 콘텐츠그룹 별 평균 이탈률을 통계적으로 비교해 보았습니다.
- 직무정보+역량요소의 포함 여부와 이탈률
- S요소+H요소의 포함 여부와 이탈률
- 상담요소+Q요소의 포함 여부와 이탈률
- 자소서+P요소+I요소의 포함 여부와 이탈률
- … 등등
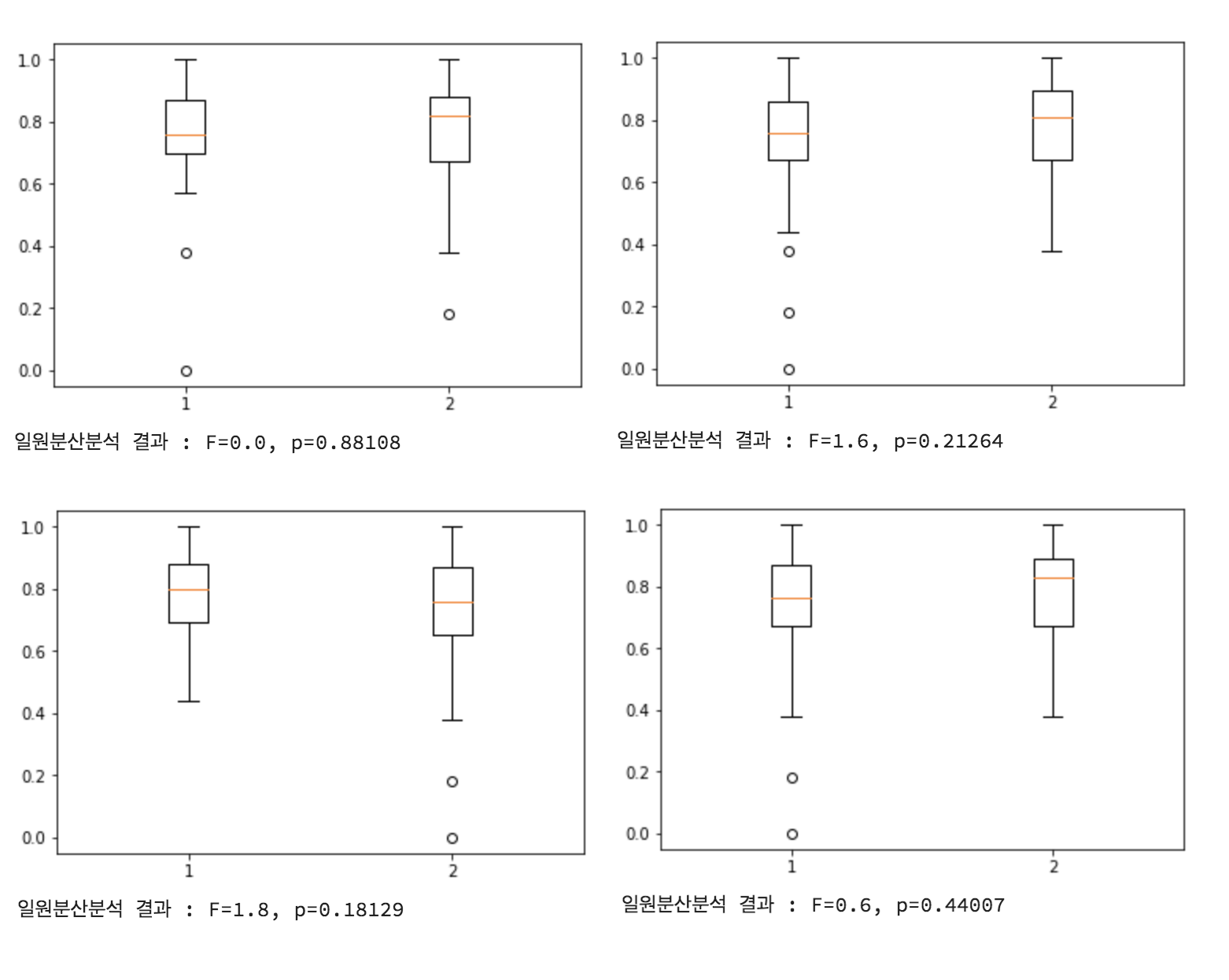
< 통계적으로 무의미한 결론의 연속 >
동시에 여러 요소들을 가지고 있는 콘텐츠를 비교하다보니, 정확히 어떤 요소가 이탈률의 차이를 만들어내는 지 명확하게 드러나지 않았습니다. 따라서 이후에는 각 요소 하나씩 만을 기준으로 하여 해당 요소를 포함/미포함 콘텐츠로 나누어 box-plot과 ANOVA검정을 다시 진행해 보았습니다. 그리고 그 결과 다른 요소들 보다 눈에 띄게 평균 이탈률에 차이를 유발한 요소를 하나 발견하였습니다.
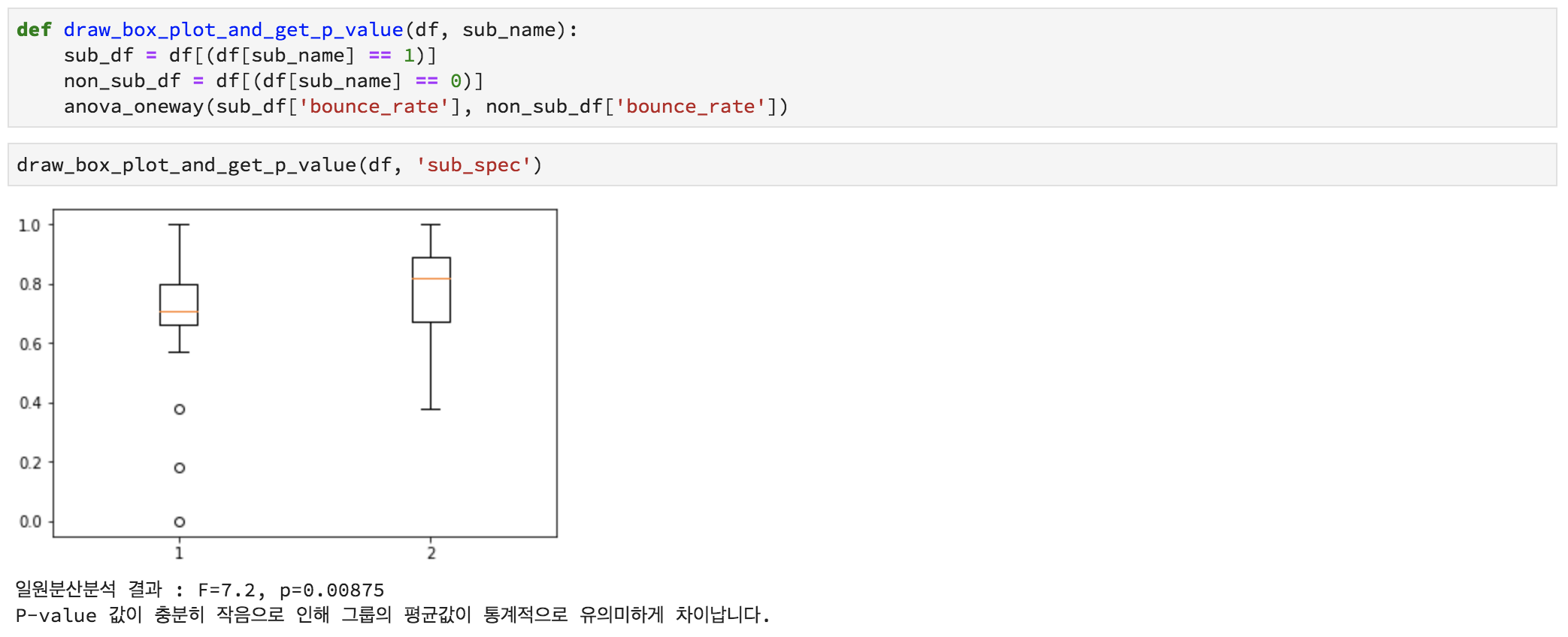

< S요소를 포함/미포함하는 콘텐츠의 평균 이탈률 비교 >
결과부터 말씀드리자면, 답은 “S요소” 이었습니다. S요소를 포함하는 콘텐츠들은 다른 콘텐츠들보다 평균이탈률이 낮았고, 글을 읽은 후 유저들이 추가적인 탐색을 진행했다고 볼 수 있었습니다. 이후 S요소가 포함된 콘텐츠들을 따로 뽑아내어 내용을 확인해보니, 확실히 직무나 업무에 관한 요소들, 혹은 자소서나 면접과 같은 일반적인 콘텐츠보다 ‘개인화’되어 있다는 느낌이 많다는 특징이 있었습니다. 그리고 이렇게 하여 S요소를 대표님께 드릴 보고서에 당당하게 추가할 수 있었습니다.
콘텐츠 카테고리 분석
콘텐츠는 실제로 유저들이 주고 받은 질문과 답변을 가공한 글입니다. 수만개의 질문, 답변 중 콘텐츠로 발행할만한 가치가 있는 것을 선별하고 편집과 퇴고를 거쳐 발행을 하게 됩니다. 콘텐츠의 선별 기준은 다음 3가지입니다.
- 콘텐츠화 하기에 적당한 분량인가
- 좋은 답변, 충실한 답변인가
- 적절한 카테고리인가
“적절한 카테고리”란 한 카테고리에 콘텐츠가 몰려있지 않고 모든 카테고리에 콘텐츠를 고루 발행했는가를 의미합니다. 여기에는 다음과 같은 전제가 깔려있습니다.
“카테고리 별 콘텐츠 개수가 사용자의 유입과 이탈에 영향을 미칠 것이다.”
정말 카테고리 별 콘텐츠 개수와 유입, 이탈은 관련이 있을까요? 이 전제를 분석해보기로 했습니다.
카테고리 내 콘텐츠 개수가 많을수록 이탈률이 낮지 않을까?
콘텐츠 카테고리는 총 20개이고 콘텐츠 갯수가 0개인 2개의 카테고리를 제외하면 18개의 카테고리가 분석 대상입니다. 만개가 넘는 사용자 데이터에 비하면 턱없이 부족하기 때문에 유의미한 결과를 얻기 힘들겠다는 생각을 하며 세부 분석에 들어갔습니다.
일단 콘텐츠 개수와 이탈률의 관계를 알아보기 위해 산점도를 그렸습니다. 유의미한 패턴을 기대했으나 18개의 점들은 패턴 없이 그래프 상에 퍼져있었습니다. 콘텐츠 개수와 페이지뷰, 콘텐츠 개수와 세션도 마찬가지였습니다.
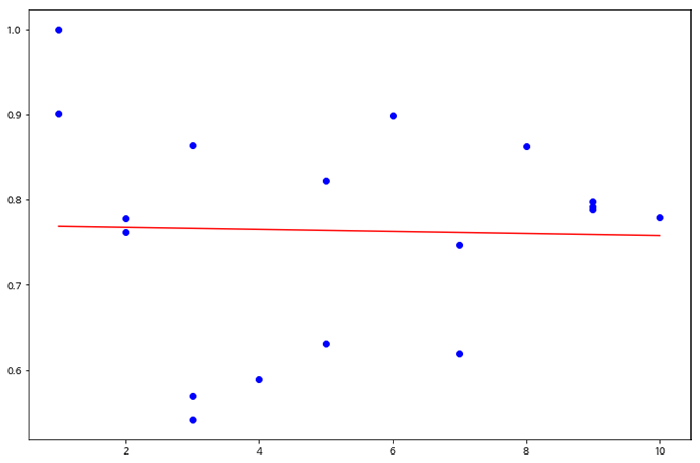 < 콘텐츠 개수와 이탈률의 관계 그래프 >
< 콘텐츠 개수와 이탈률의 관계 그래프 >
대신 다른 카테고리에 비해 이탈률이 특히 높은 카테고리에 눈이 갔습니다. 이탈률이 90%, 100%로 가장 높았고 이 둘 모두 글이 1개뿐이라는 공통점이 있었습니다. 또한 이탈률이 가장 낮은 카테고리는 글의 개수가 5개로 10개의 글을 가진 카테고리보다 이탈률이 낮았습니다. 전제와 다르게 카테고리 내 콘텐츠 개수와 이탈률은 크게 관계가 없었습니다.
그렇다면 콘텐츠 이탈률과 관련 있는 요소는 뭘까?
이탈률과 관련 있는 요소를 찾기 위해 이탈률과 페이지뷰, 이탈률과 세션 간 산점도를 그려보았습니다. 첫번째 분석보다는 어느 정도 패턴이 보이는 것 같아 아웃라이어를 제외하고 다시 산점도를 그려보았습니다.
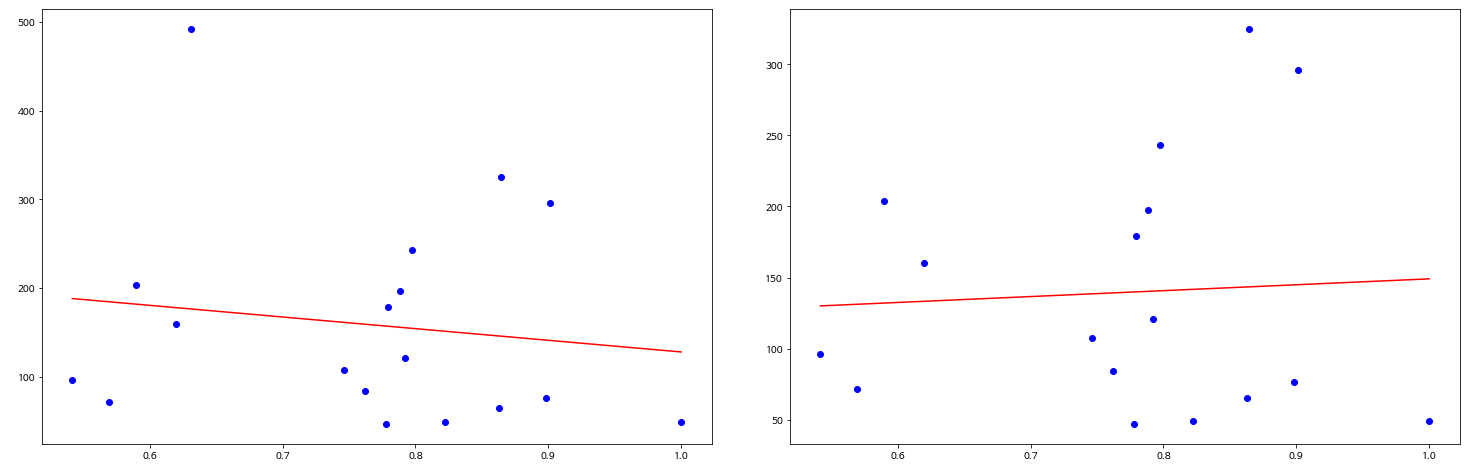 < (좌)아웃라이어가 포함된 이탈률과 페이지뷰 그래프 (우)아웃라이어가 제거된 이탈률과 페이지뷰 그래프 >
< (좌)아웃라이어가 포함된 이탈률과 페이지뷰 그래프 (우)아웃라이어가 제거된 이탈률과 페이지뷰 그래프 >
아웃라이어를 제외하면 제외하기 전과 달리 기울기가 음수에서 양수로 바뀌었습니다. 페이지뷰 수가 높은 콘텐츠일수록 이탈률도 높다고 볼 수 있지만 오차가 존재하고 추세선의 기울기 크기도 크지 않았습니다. 데이터가 더 많았다면 유의미한 결론을 내릴 수 있었겠지만 두 요소의 관계를 확인하는 것에 의의를 두고 분석을 마무리하였습니다.
유저 그룹으로 나누기
이탈률을 줄이는 방법은 크게 두 가지가 있습니다. 이탈하는 유저를 줄이는 방법도 있겠지만, 유입되는 유저를 늘리는 방법도 있습니다. 신규 유저 중에서 이탈하지 않은 유저들은 어떤 채널에서 유입되었는지, 웹사이트에서는 얼마나 오래 머무르는지 등을 이 분석에서 알아보도록 하겠습니다.
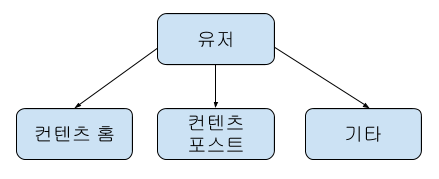
Landing Page (유저가 최초로 보게 된 페이지)를 컨텐츠 홈, 컨텐츠 포스트 그리고 기타 페이지로 나누어서, 각 페이지의 평균 이탈률을 확인했습니다.
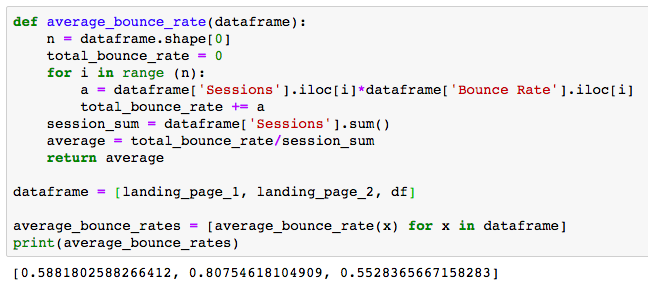
컨텐츠 홈으로 유입된 유저들의 이탈률은 58%, 컨텐츠 포스트로 유입된 유저들의 이탈률은 80%가 나왔습니다. 둘 다 평균(55%)보다 더 높은 이탈률을 보이며, 특히 컨텐츠 포스트로 유입된 유저들의 이탈률이 높습니다.
헤비유저 정의하기
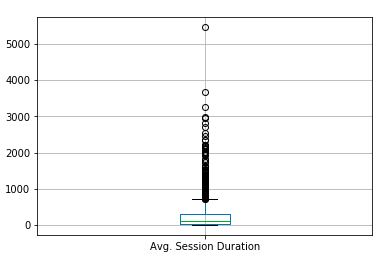
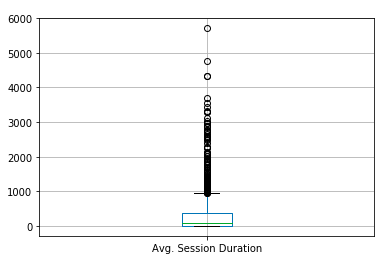
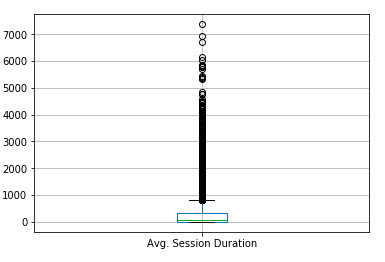
각 그룹의 세션당 체류시간을 Boxplot으로 그려보았습니다. Boxplot은 수치적 자료를 보여주는 그래프이며, 흔히 데이터의 분산 및 이상치(outlier)를 탐색하기 위해서 사용됩니다. 그려보니 확연하게 이상치가 나타나는 것을 볼 수 있고, 이를 토대로 평균 유저보다 더 오래 웹사이트에 머무르는 ‘헤비 유저’를 정의했습니다.
3개의 Boxplot에서 이상치가 1000초 이상에서 나타나는 공통점을 볼 수 있습니다. 그리하여 저희는 ‘헤비 유저’를 1000초 이상 웹사이트에 체류하는 유저로 정의했습니다.
유저 유입 분석하기
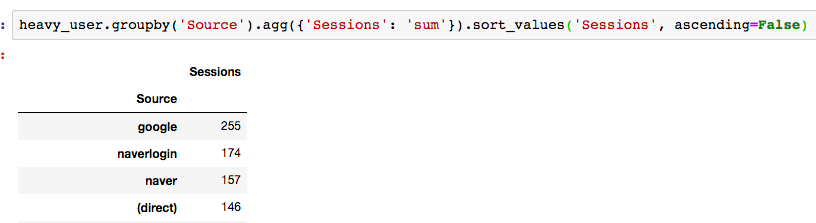
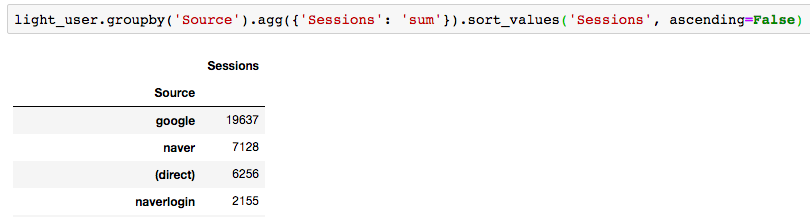
‘헤비 유저’와 ‘라이트 유저(헤비 유저를 제외한 나머지)’로 나누어서, 유입에 차이가 있었는지 분석해보았습니다. 하지만 크게 유의미한 차이는 나타나지 않았습니다. 둘 다 대부분 구글이나 네이버 등의 검색 엔진에서 유입되는 것을 알 수 있었습니다.
유저 행동 분석하기
유저들의 유입은 큰 차이가 없었지만, 이탈률에서는 차이가 난다는 점이 발견되었기에 ‘헤비 유저와 라이트 유저는 웹사이트에서 다른 의도를 가지고 행동을 할 것이다’라는 가설을 세우게 되었습니다.
가설과 관련된 분석은 유저 행동 분석이 되었고, 이를 Google Analytics에 있는 User Explorer를 이용해서 진행하였습니다.

User Explorer를 이용하면 GA가 track한 유저들의 행동 정보 - 클릭한 페이지, 각 페이지에 머문 시간 - 등을 상세하게 볼 수 있습니다. 2만개의 이상의 유저 정보를 볼 수 있었지만, GA 무료 버전에서는 자동화를 할 수가 없어서 모든 유저 정보를 분석하기에는 힘들었습니다.
그리하여, ‘헤비 유저’와 ‘라이트 유저’에 해당하는 유저들을 샘플링하여, 그들의 행동에서 유의미한 패턴을 찾아볼 수 있는지 분석하였고, 그 결과 이와 같은 패턴을 발견하였습니다.
- ‘헤비 유저’ - 컨텐츠 보다는 웹사이트의 다른 서비스를 이용하는 경향이 있다.
- ‘라이트 유저’ - 자신의 관심사와 연관된 컨텐츠를 보는 경향이 있다. 컨텐츠에 검색 기능이 완성되지 않아서, 다른 페이지로 이동하기도 했다.
그리하여 새로운 유저들을 유입하려면, 그들의 관심사에 맞는 컨텐츠를 제작해야 하며, 검색 기능을 추가하는 UX적인 제안을 회사에 하게 되었습니다.
쉽지 않네 이거…
데이터가 적었기에 코드를 작성하는 시간은 적었지만 그래프를 어떻게 해석해야 하는지, 데이터를 어떤 형태로 봐야 지금보다 더 유의미한 결과를 얻을 수 있을지 고민하는 시간이 훨씬 길었습니다. 수치적인 해석을 하고 싶어 몇몇 통계 이론도 적용해 보았지만 데이터가 적어서인지 생각과 다른 결과들이 나왔습니다.

적은 데이터의 한계를 인지하고 분석을 진행했기에 분석 결과에 크게 실망하지는 않았습니다. 지금보다 더 많은 경험과 지식을 쌓으면 유의미한 결과를 낼 수 있을 것이란 희망을 품어봅니다.